The situation
The college’s IT and Maintenance team managed around 900 tickets per month across email, Microsoft Teams, the self-service portal, and phone. Requests were being handled, but the operating model was too manual — most arrived as generic tickets, problem management was missing, routing wasn’t structured, and leadership lacked reliable visibility into service performance.
The organisation also wanted to expand service management beyond IT, starting with Facilities. The new platform needed to support multi-team service delivery, not just replace the old ticket queue.
This was not a greenfield build. Around 71,000 historical tickets sat in SolarWinds, with roughly 200 still open and needing to continue through the transition — and in a school environment, the service desk had to keep running throughout. There was no room for a disruptive cutover.
What we did
Opsaro structured the work across five weeks to keep decisions moving and minimise disruption.
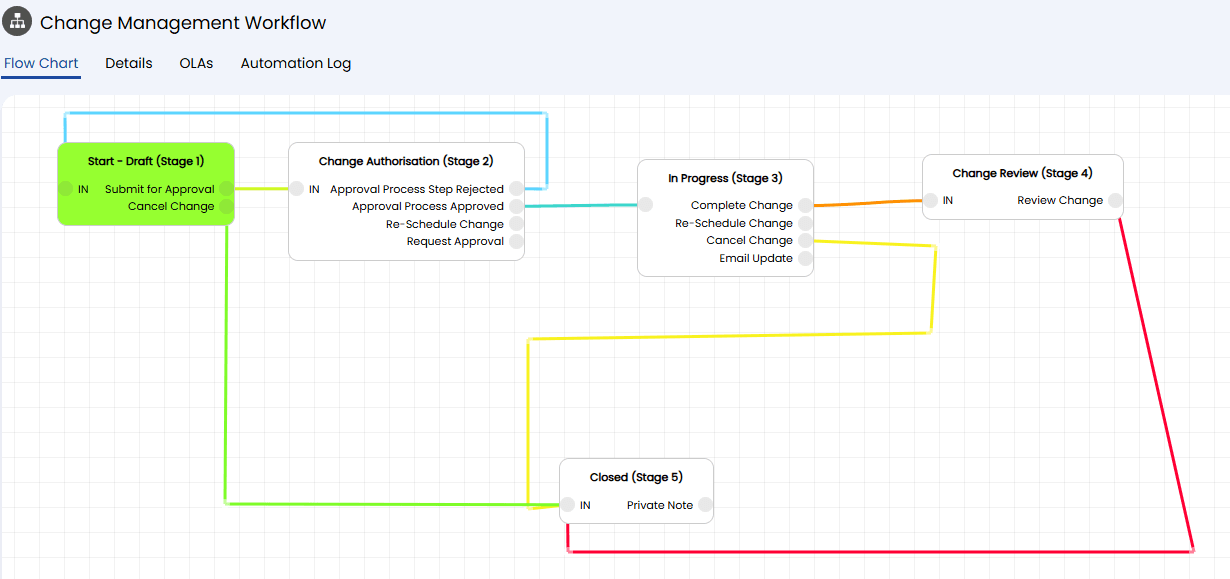
Weeks 1–2 covered discovery and architecture: mapping real workflows (not just documented ones), defining request types, building a 97-value categorisation taxonomy, configuring RBAC, aligning SLA targets, and starting asset import from spreadsheet and Intune sources.
Weeks 2–3 focused on reducing manual effort: automated assignment rules, a SQL department lookup, a simplified change workflow, resource booking, and email templates.
Weeks 3–4 added structured problem management — creating problems from incidents, linking related incidents, assigning problem managers, and updating stakeholders from one place.
Week 5 was migration and go-live: open tickets moved from SolarWinds, SSO confirmed for agents and end users, mailbox cutover completed, and hyper-care started immediately. Workshops and configuration decisions were recorded in Loom as a reference library, and the service desk stayed operational the entire time.
The outcome
The biggest shift was not just the platform — it was how the team worked. Cybersecurity alerts could be managed through problem records with linked child incidents. Duplicate tickets became easier to handle, and structured closure codes gave leadership real insight into what was being resolved and how.
Agents adopted the system quickly, supported by recorded workshops and a Loom reference library. Rather than simply replacing a ticket queue, the platform became an ESM-ready foundation — structured to support future expansion beyond IT, starting with Facilities.
The detail
Project detail and what was delivered.
The specifics behind the headline results — the environment, the capabilities configured in HaloITSM, and the before and after measures.
Sector
Education
Users
Approximately 1,200 students, 150 staff, parents, and internal service users.
Service team
20-person IT and Maintenance team supporting requests across multiple channels.
Previous platform
SolarWinds service desk environment with a largely generic ticket model.
New platform
HaloITSM configured for IT service delivery and future enterprise service management expansion.
Project type
Migration, implementation, workflow redesign, reporting uplift, and go-live support.
What changed
Specific capabilities delivered in HaloITSM.
Beyond standard platform configuration, these changes improved how the team worked day to day.
97 category values
A structured taxonomy replaced the previous generic ticket approach and supported better routing, reporting, and operational insight.
Problem management
Incidents can now be linked to problems, assigned to problem managers, and updated in bulk where related incidents need coordinated communication.
SQL department lookup
Portal request forms can automatically populate the requester’s department while still allowing the user to adjust the value where needed.
Resource booking workflow
A custom workflow was configured for student and staff equipment loans, supporting clearer request handling and fulfilment.
Simplified change enablement
The RFC workflow was streamlined with cleaner approval stages, CAB approval groups, and ad-hoc stakeholder communication actions.
Scheduled reporting
Scheduled reports were configured, including quarterly change summaries and operational alerts such as secret key expiry reporting.
Loom documentation library
Workshops and configuration decisions were recorded so administrators and agents had a practical reference after implementation.
Ticket migration
Approximately 71,000 historical tickets and around 200 open tickets were migrated from SolarWinds into HaloITSM.
ESM-ready foundation
The platform was structured to support future expansion beyond IT, including planned onboarding of Facilities as a non-IT service team.
The results
A measurable uplift in service management performance.
Within the first three months after go-live, the service desk had clearer categories, better reporting foundations, and stronger operational control.
| Area | Before | After | Outcome |
|---|---|---|---|
| SLA compliance | 74% | 93% | Improved service performance visibility and stronger operational control. |
| Ticket categorisation | Generic or limited categorisation | 97 category values | Clearer routing, reporting, and service demand analysis. |
| Migration | 71,000 historical SolarWinds tickets | Migrated to HaloITSM | Historical context retained while the team moved into the new platform. |
| Open work | ~200 active tickets | Migrated for continuity | Active work continued through cutover without losing operational context. |
| Time to go-live | No strict project timeline culture | 5-week implementation | Structured delivery kept decisions moving and supported a clean launch. |
| Future service expansion | Primarily IT-focused service desk | ESM-ready HaloITSM foundation | Prepared for future Facilities onboarding and broader service management use cases. |

What changed in the standard approach
Training became more formalised after this engagement.
Recorded workshops and Loom videos were effective, and agents were productive from day one. However, the client later noted that more formalised, role-based training would have added value.
That feedback has since been built into Opsaro’s standard engagement model, with clearer training phases for agents, end users, administrators, and leadership where appropriate.
Get started
Want a result like this?
Tell us what you are trying to build, fix, or improve and we will help identify the best next step.
A 30-minute call. No prep needed. We usually reply within one business day.