How a Perth private college replaced SolarWinds with HaloITSM, migrated 71,000 tickets, and built a platform ready for enterprise service management, all without a single day of downtime.

A prestigious private college in Western Australia serves approximately 1,200 students, 150 staff as well as parents. Their 20–person IT and Maintenance team had been running a legacy service desk platform for years, managing around 900 tickets per month across email, Microsoft Teams, a self-service portal, and phone calls.
On the surface, it worked. Tickets came in, tickets went out. But underneath, everything was manual. There were no structured categories, or different ticket types. Every request landed as a generic ticket. Merging duplicate tickets was painful. There was no problem management, no automated routing, and no real visibility into what was happening across the department. SLAs existed on paper but nobody trusted the numbers.
When leadership decided to expand beyond IT into enterprise service management (starting with Facilities), they realised their existing platform couldn’t grow with them. They needed a solution that could handle multi-department service delivery, and they needed someone who could get them there without disrupting a highly routine-driven environment.
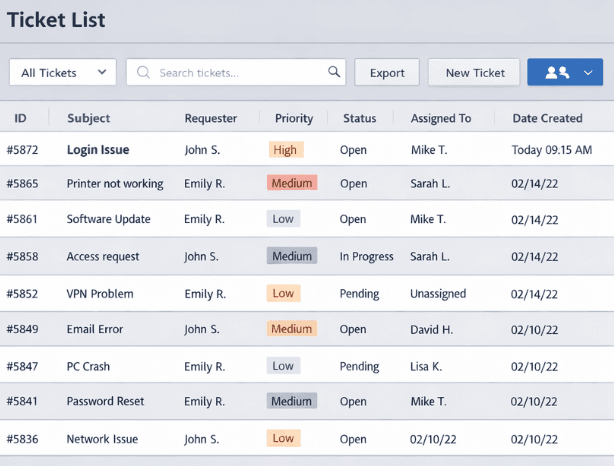
This wasn’t a greenfield build. The college had 71,000 historical tickets in SolarWinds with roughly 200 of them still open.
These needed to come across. No significant impact to users, or agents.
The team had to stay operational throughout the transition; in a school environment, you can’t tell staff and students to “just wait” while the service desk is offline.
Thousands of registered devices, stringent network policies, and examination dates that cannot wait.
There was also no strict project timeline culture in place. The IT team were good operators but they hadn’t been through a structured implementation before. Any approach that relied on the customer driving the project independently wasn’t going to work. They needed someone to own the delivery, keep them accountable, and make decisions quickly when configuration questions came up.
We ran this as a 5-week engagement, from kickoff to go-live including the migration of open SolarWinds tickets. The structure was built around keeping momentum high and decisions fast. Every workshop was recorded, and configuration was documented through Loom videos that became the team’s ongoing reference library.
Two weeks of working sessions with the IT and Maintenance team. We mapped their actual request types, built a categorisation taxonomy of 97 values (replacing the previous "everything is a generic ticket" approach), configured RBAC, and aligned SLA targets to what the team could realistically deliver. Asset imports from both spreadsheet and Intune were completed in parallel.
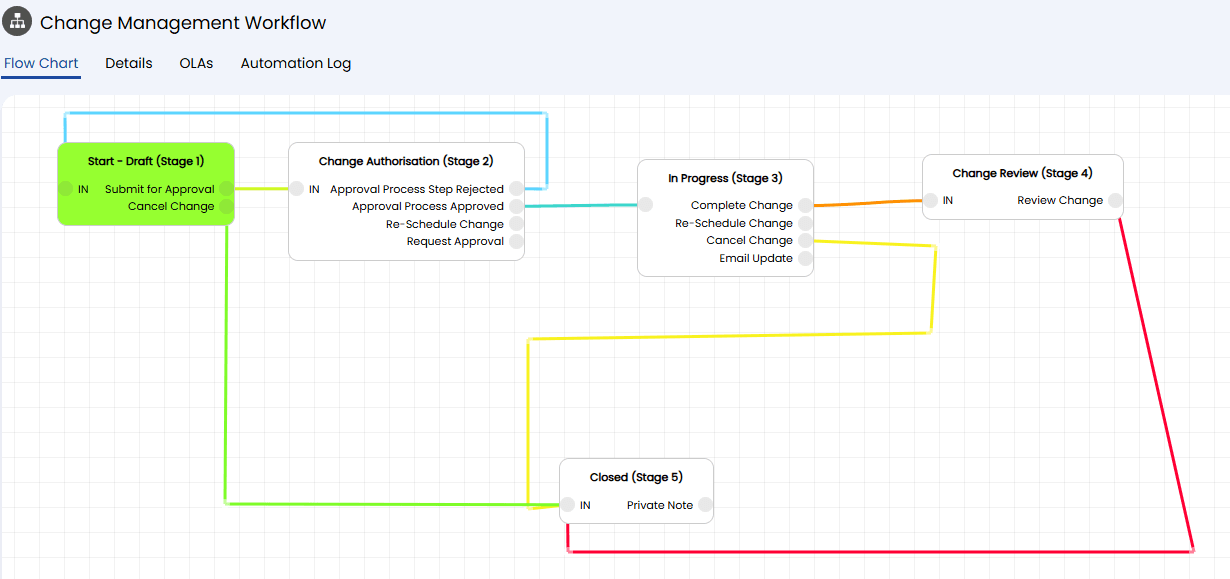
This is where the platform started doing work the team used to do manually. We built an SQL lookup that auto-populates the user's department when they raise a request (but still lets them change it). We simplified the RFC workflow, collapsing authorisation and in-progress into a cleaner flow with CAB approval groups for normal and emergency changes. We configured a custom resource booking workflow for loan equipment, ad-hoc change communication actions, email templates, and ticket rules for automated assignment based on category.
This was the capability they didn't have before and wanted most. We configured the ability to create problems from incidents - particularly for cybersecurity alerts, where the team can now raise a problem, assign a problem manager, link related incidents, and update all stakeholders from a single action. We also set up Entra ID integration for user and agent imports, configured the self-service portal CSS, and built scheduled reports including a quarterly change summary.
Open tickets migrated from SolarWinds. SSO confirmed for all agents and end users. Mailbox cutover completed mid-week. All recorded workshop sessions served as training material - agents picked up the new system quickly. Hypercare began immediately after cutover with continual availability through Teams.
Beyond the standard platform configuration, these were the specific capabilities that changed how the team works day-to-day
Within the first three months of go-live, the numbers told the story clearly:
But the numbers only tell half the story. The shift that mattered most was operational. The team went from a platform where every ticket looked the same and every action was manual, to one where cybersecurity alerts automatically become problems with assigned owners, duplicate tickets merge in two clicks (something that was “very hard” in SolarWinds), and closure codes give leadership actual data on what’s being resolved and how.
Agents picked up the new system quickly — the recorded workshops and Loom documentation meant there was always a reference to go back to. The only feedback for improvement was that training could have been more formalised and structured, something we’ve since built into our standard engagement model.
The platform is now the foundation for the college’s ESM expansion. The Facilities department is currently being scoped for onboarding — the first non-IT team to run through Halo — and the 97-category taxonomy is designed to extend rather than rebuild.

Training. The recorded workshops and Loom videos worked, with agents productive from day one. But the client told us they would have valued more formalised, structured training sessions. We've since built a dedicated training phase into our standard engagement model with role-based sessions for agents, end users, and leadership.
